|
I am a third-year (starting from 2023) Ph.D. student at University of California, Santa Cruz, supervised by Prof. Cihang Xie and Prof. Yuyin Zhou. Before joining UCSC, I was a researcher at Tencent. Previously, I got the Master degree at SUN YAT-SEN UNIVERSITY in 2021, supervised by Prof. Wei-Shi Zheng. Before that, I received my B.Eng. from Sichuan University in 2019. My research interests lie in deep learning and computer vision. I have published several works on image and video perception, as well as multimodal learning. Currently, I focus on generative AI, multimodal large language models, and large language models. Feel free to reach out to me at jinruiyang.ray@gmail.com for discussions or opportunities.
CV / Google Scholar / Github |

|
|
|

|
Research Intern Oct 2025 – Present · San Jose, CA Advisor: Yu Tian and Xueqing Deng |

|
Research Intern · Jun 2025 – Oct 2025 · San Jose, CA Advisor: Ohi Dibua Research Intern · Jun 2024 – Jun 2025 · San Jose, CA Advisor: Qing Liu and Zhe Lin |

|
Researcher · Full-time Jul 2021 – Aug 2023 · Shanghai, China Research Intern · May 2020 – Oct 2020 · Shanghai, China |
|
|
(*: Equal contribution) |

|
Jinrui Yang, Qing Liu, Yijun Li, Mengwei Ren, Letian Zhang, Zhe Lin, Cihang Xie, Yuyin Zhou paper (coming soon)/ page LASAGNA is a unified framework for controllable layered image generation that jointly synthesizes coherent composites, clean backgrounds, and transparent foregrounds with realistic visual effects (e.g., shadows and reflections) to enable flexible and precise real-world image editing. |

|
Jinrui Yang*, Zonglin Di*, Ohi Dibua, Qing Liu, Seun Adekunle, Daniil Pakhomov, Darshan Ganesh Prasad, Cihang Xie, Yuyin Zhou. paper (coming soon) We introduce MMOCCLU and PARALLAX, an RL-trained vision–language model that learns occlusion-aware reasoning with precise grounding (mask/box/point), improving occlusion understanding while preserving general VLM performance. |

|
Jinrui Yang, Qing Liu, Yijun Li, Soo Ye Kim, Shilong Zhang, Daniil Pakhomov, Mengwei Ren, Jianming Zhang, Zhe Lin, Cihang Xie, Yuyin Zhou CVPR, 2025 paper/ page LayerDecomp outputs photorealistic clean backgrounds and high-quality transparent foregrounds with faithfully preserved visual effects. |
|
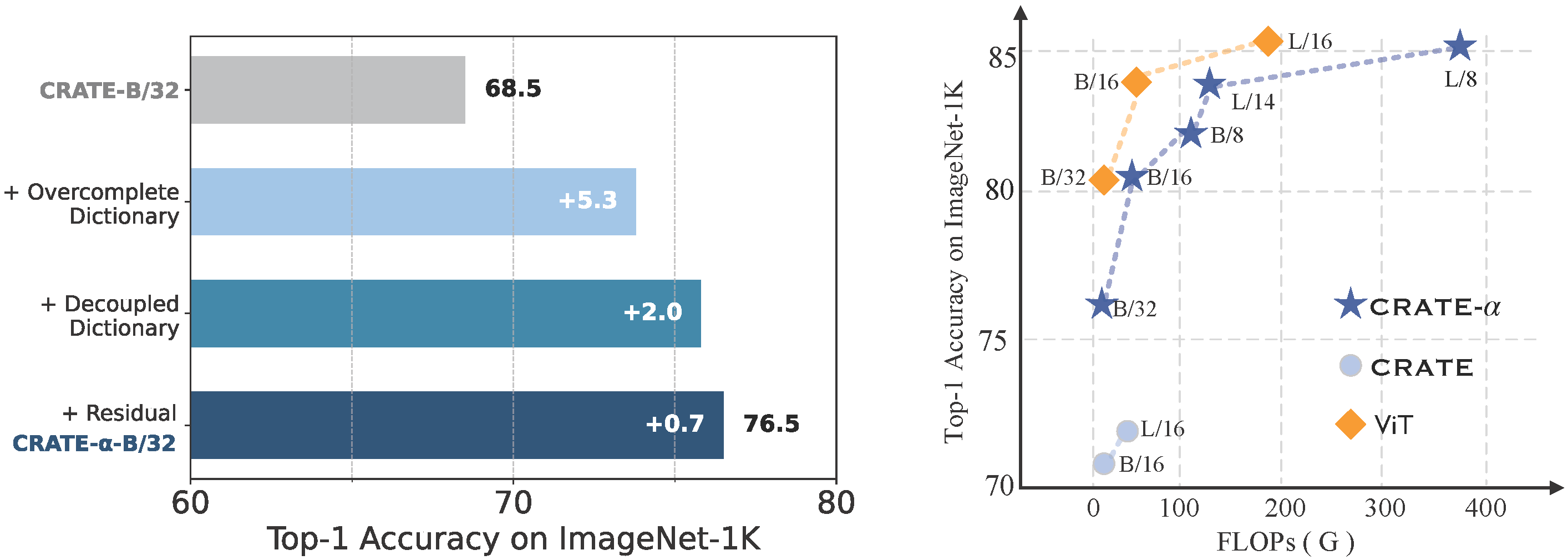
Jinrui Yang*, Xianhang Li*, Druv Pai, Yuyin Zhou, Yi Ma, Yaodong Yu, Cihang Xie NeurIPS, 2024 paper/ page/ code/ 新智元 We scaled the white-box transformer architecture, resulting in the CREATE-α model, which significantly improves upon the vanilla white-box transformer while preserving interpretability. This advancement nearly closes the gap between white-box transformers and ViTs. |

|
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, Yunsheng Wu, Rongrong Ji NeurIPS, 2025 (Highlight) paper/ page/ code/ 新智元 The paper introduces the first comprehensive Multimodal Large Language Model (MLLM) evaluation benchmark, MME. It measures both perception and cognition abilities across 14 subtasks, with 30 advanced MLLMs evaluated comprehensively on MME. |
|
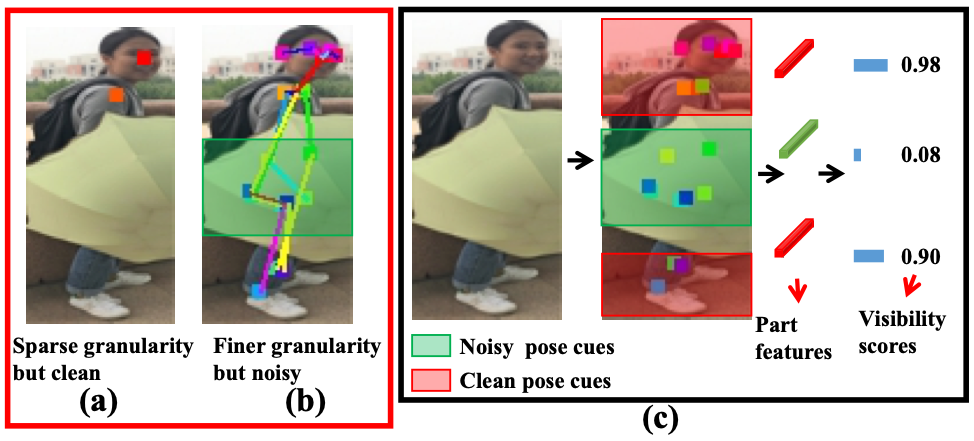
Jinrui Yang, Jiawei Zhang, Fufu Yu, Xinyang Jiang, Mengdan Zhang, Xing Sun, Ying-Cong Chen, Wei-Shi Zheng ICCV, 2021 paper We propose a novel method to discretize pose information into visibility labels for body parts, ensuring robustness against sparse and noisy pose data in Occluded Person Re-ID. |
|
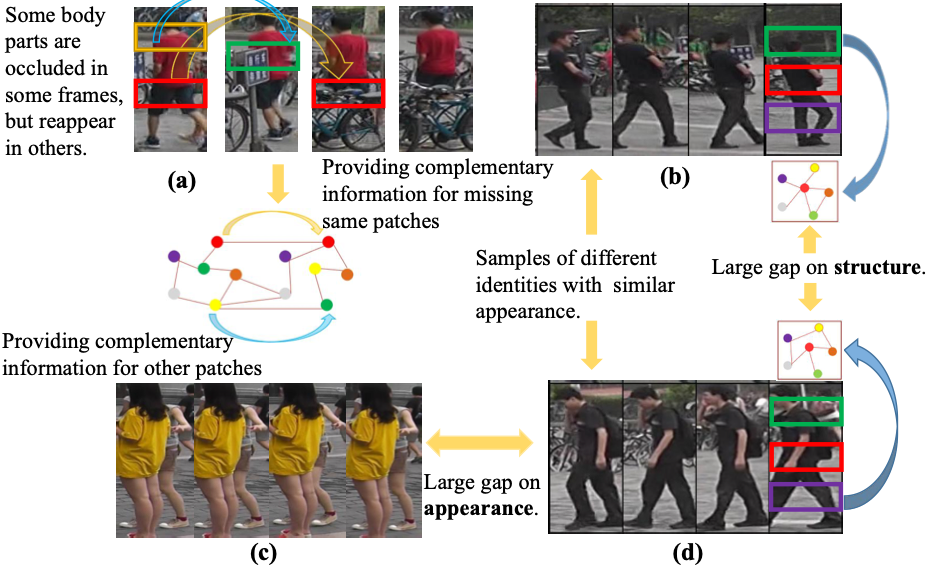
Jinrui Yang, Wei-Shi Zheng, Qize Yang, Ying-Cong Chen, Qi Tian CVPR, 2020 paper We propose a novel Spatial-Temporal Graph Convolutional Network (STGCN) to address the occlusion problem and the visual ambiguity issue caused by visually similar negative samples in video-based person Re-ID. |
|
Reviewer
|
|
|
Design and source code from Jon Barron's website |